In this I will follow my preffered briefing method the WHAC method.
What?
Compressed video formats produced different modalities which includes i-frames, p-frames, b-frames and audio. A recent beautiful work from WACV 2022, produced four transformer-based architectures to fuse these four modalities in an interesting way.
Using the base Vit and ViViT models, MM-ViT scored better or equally nearby scores on UCF101, Kinetics 600 and SomethingSomethingv2 (without audio dataset).
This approach has mapped each modality into a representation compatible with transformer architecture which expects a parallel input in the form of patches/tokens.
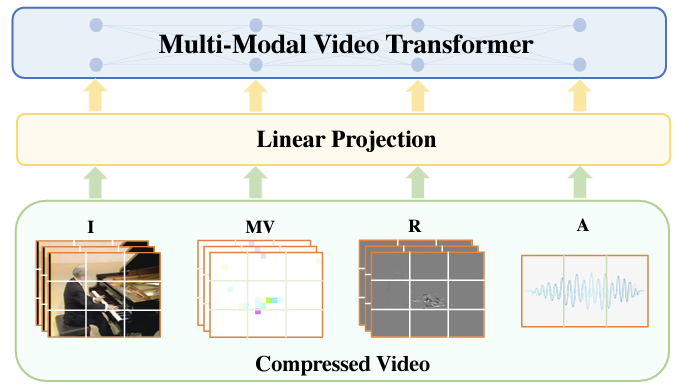
This work has different interesting parts.
How?
MM-ViT converts non-audio modalities in a different way as compared to audio modality. Basically, waveform has been used for audio representation. Transformer-based abstract variables (query, key, value) were extracted for each modality and are passed through an MLP to the attention mechanism. As mentioned four, there are four different architectures named different on the basis of key module they use.
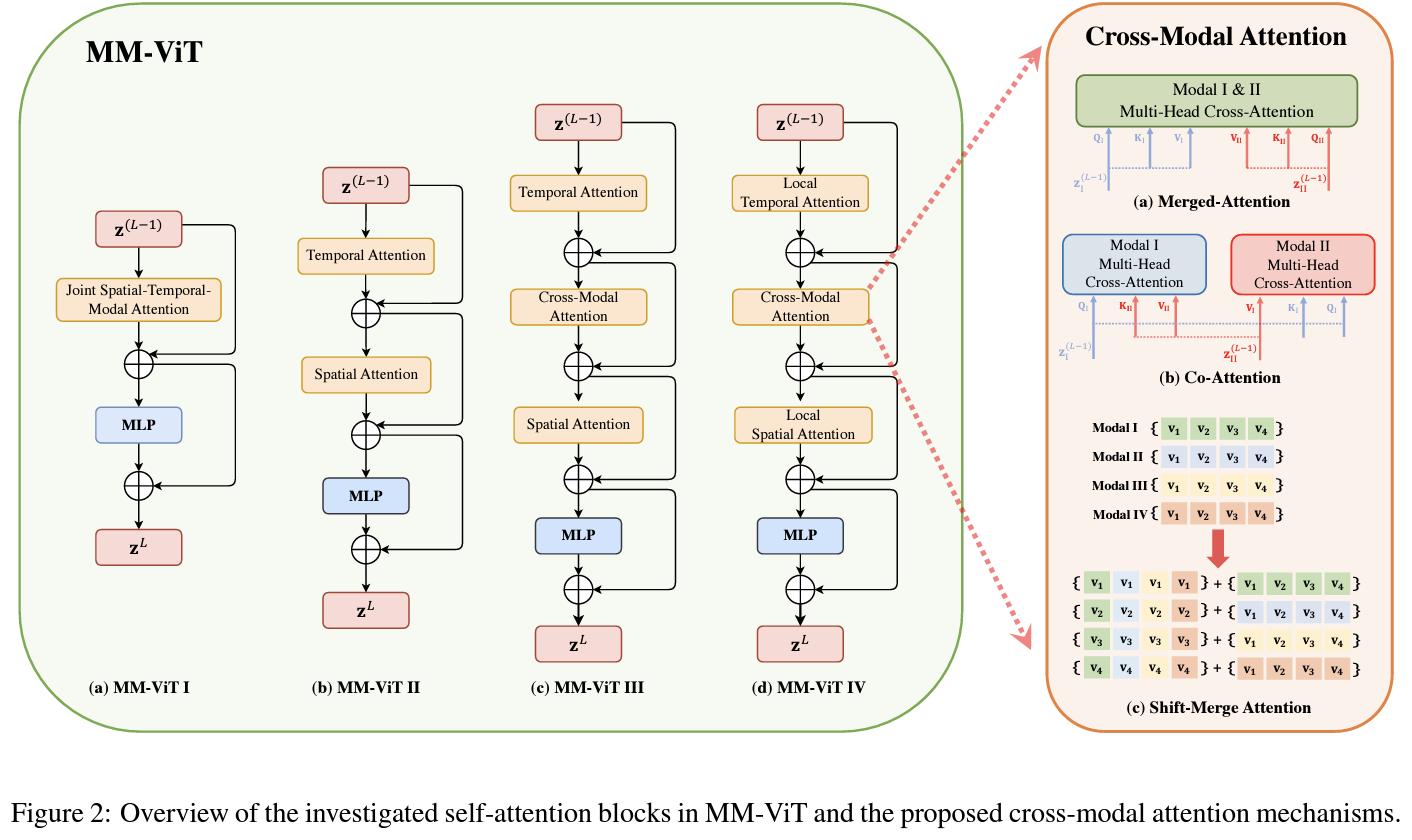
Are we sure?
MM-ViT III is the best variant produced which has beaten SOTA CNN variants with and without optical flow. MM-ViT is efficient as it does not perform the heavy duty for optical flow. For qualitive view of the work picture generated from attention weights have been shared in the manuscript.
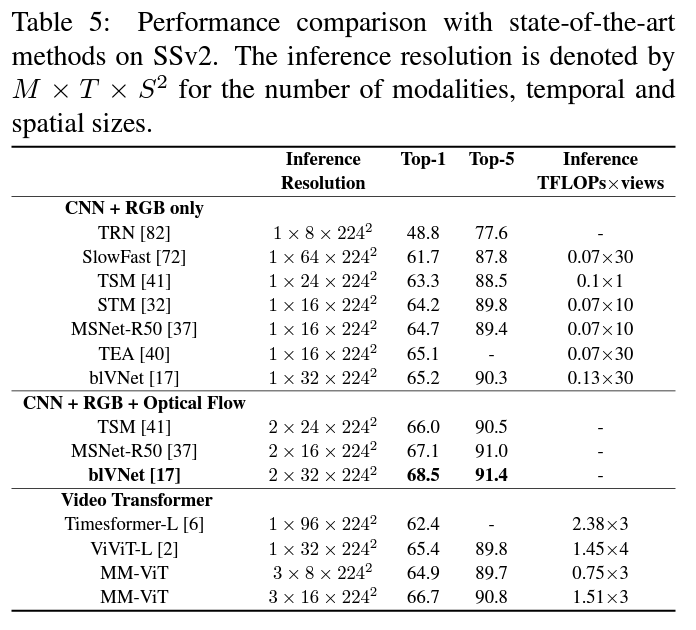
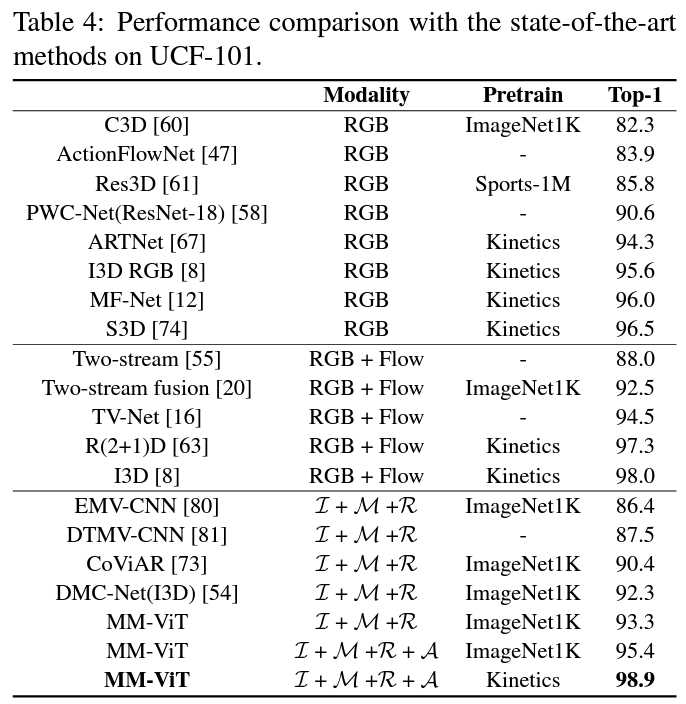

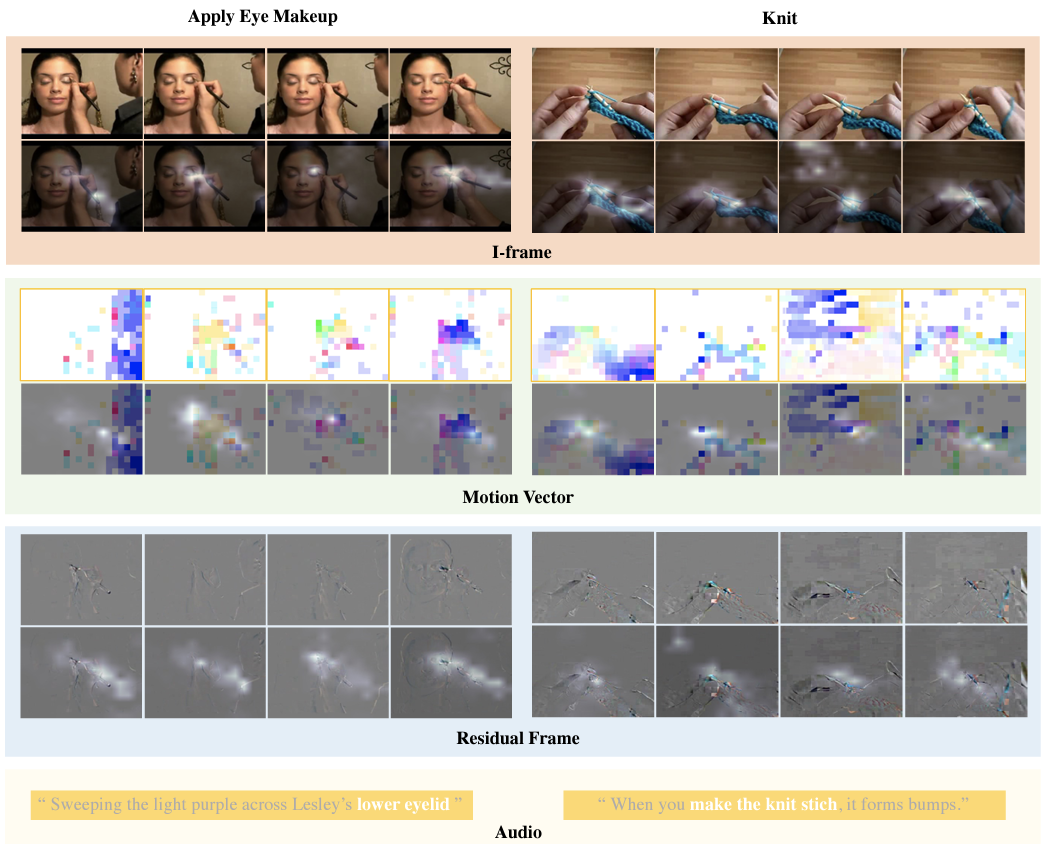
Can I do it?
Key candidates for implementation are
Critical Details
- SSv2 has no audiostream
- all compressed videos to MPEG-4 codec which encodes a video into I-frames and P-frames.
- Patch size is set to 16×16 across the visual modalities.
- ViT-B pretarined on ImageNet-21K is the backbone
- SGD with batch size 8
- Learning rate starts from 0.5 and is divided by 10 when the validation accuracy plateaus.
- 83 refs which is huge
- bad- table layout is not consistent
- bad- mehcanisms diagram needs improvement
- bad-source not provided
- bad-machine details not provided
- bad-not reproducible
- bad-future works not shared
- bad-limitations not shared
- May be part of a commercial project as Oppo is a popular Computer Vision Tech-based company.